I’ve always wanted to, rather than provide the same boring ‘article’ or ’node’ thumbnails, write a script to crawl my content and generate unique thumbnails for each article. This morning, that’s exactly what I did. The current script can be viewed at /generate_thumbnails.py
generate_thumbnails, for every page with a markdown file, will generate and
save a picture that looks like this:
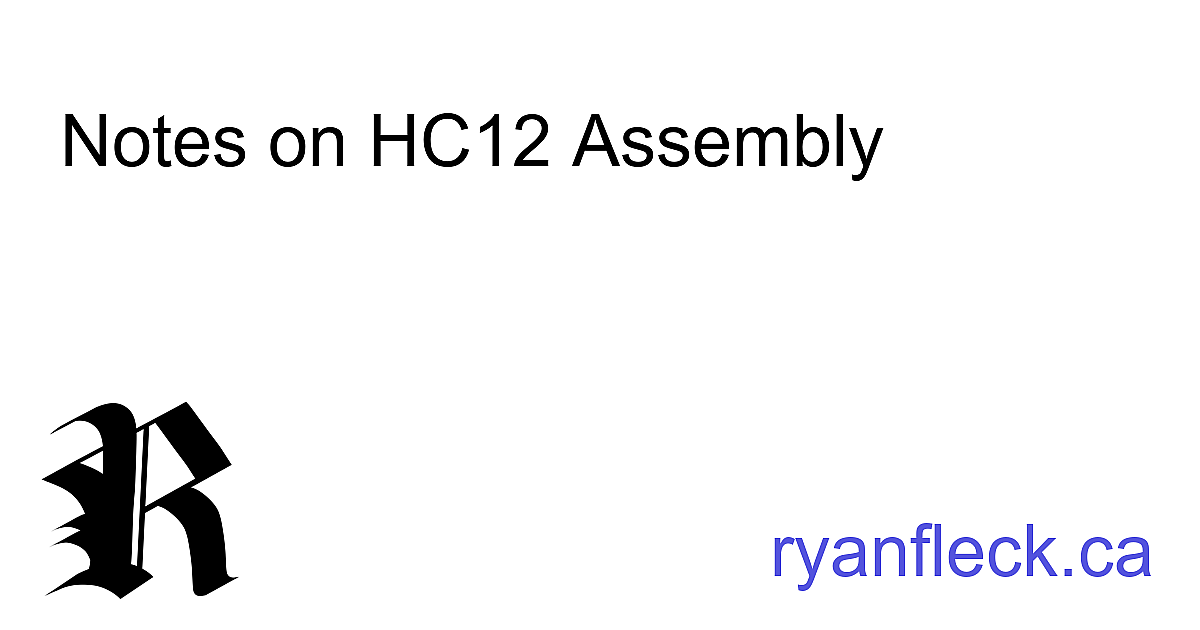
This is fairly easy to integrate into the header of each content page with Hugo.
We’ll write thumbnails to /assets/thumbnails/<article content path>.png
In your head.html partial, prepare a path to the photo if the photo exists.
<!-- If the article is an actual file, generate a thumbnail for it. -->
{{ $thumbnail := printf "%sr.png" .Site.BaseURL }}
{{ with .File }}
{{ $picture := (path.Join "assets" "thumbnails" (print .Path ".png"))}}
{{ if (and .Path $picture (fileExists $picture)) }}
{{ $image := resources.Get (path.Join "thumbnails" (print .Path ".png")) }}
{{ if $image }}
{{ $thumbnail = $image.Permalink }}
{{ end }}
{{ end }}
{{ end }}
From here, all we need to do is write a Python script to walk through our filesystem, load the titles from the text files, and write the images.
I’ll use Pillow to create a new image and paste in the calligraphic ‘R’ that I use as a logo.
From PIL, we’ll need these libraries imported:
import os
from PIL import Image, ImageDraw, ImageFont, ImageFilter
Next, walk through the content directory, find all the markdown files, and
save them into an array called files. I’ll skip this step here, so check the
source code
if you would like an example.
files = get_content_files()
image_r = Image.open('static/r.png').resize((200, 200))
for file in files:
# Get title
title = ""
with open(os.path.join(cwd, 'content', file), 'r', encoding='utf-8') as read_obj:
# Read all lines in the file one by one
for line in read_obj:
if line and 'title' in line and line.startswith('title:'):
title = line[8:len(line)-2]
break
print(f"Generating image for page '{title}'")
# Split title into lines.
title_split = title.split(" ")
n = 25
title_chunks = []
working_chunk = ""
for word in title_split:
working_chunk = working_chunk + " " + word
if len(working_chunk) > n or ':' in word:
title_chunks.append(str(working_chunk))
working_chunk = ""
title_chunks.append(str(working_chunk))
At this point, we’ve gather the path and title of each article.
We can create and begin drawing an image.
image = Image.new('RGB', (1200, 630), (255,255,255))
draw = ImageDraw.Draw(image)
font=ImageFont.truetype("arial.ttf", 72)
for chunk in range(len(title_chunks)):
draw.text((40, 100+(chunk*80)), title_chunks[chunk], fill=(0, 0, 0), font=font)
draw.text((770, 510), "ryanfleck.ca", fill=(83, 83, 221), font=font)
Let’s prepare to save the image, ensuring that the directory we’d like to save it in exists, or else we’ll get an error when we try to save the photo.
image_file_path = str(os.path.join(dir_thumbnails, file + ".png"))
image_file_directory = os.path.dirname(image_file_path)
print(f"Saving to {image_file_path} in directory {image_file_directory}")
if not os.path.exists(image_file_directory):
os.makedirs(image_file_directory)
Finally, add the ‘R’ and save the image to the assets folder.
image.paste(image_r, (40, 400))
filtered = image.filter(ImageFilter.SHARPEN)
filtered.save(image_file_path)
…and that’s it! In your header, you can now use the $thumbnail variable
in your meta to provide web crawlers with a link to your content thumbnail:
<meta property="og:image" content="{{ $thumbnail }}" />
<meta property="twitter:image" content="{{ $thumbnail }}" />
Hopefully, after reading this, you’ll be able to use the Pillow library to create personalized thumbnails for all your own content.
Thanks for reading!