OpenIE-style triple extraction seems to be on the rocks in 2025. After a short conversation with ChatGPT I have decided to stick with legacy methods of triple extraction from text until I can secure a Mac Mini and give up (like everyone else, including the NLP researchers,) and use an LLM as a one-shot triple extractor.
It is worrying that this branch of computer science has been completely surpassed by generative AI - but hey, the future is now, and I have goals that require knowledge graphs to be built!
This article captures my journey amongst traditional machine-learning NLP libraries to find the best one to build knowledge graphs with a small compute budget (a 2c/4t i3 box sitting in my laundry room.)
Navigation Aid
This lengthy article has a button in the top-right corner of the page to quickly jump back to the Table of Contents.
It looks like this ToC
CoreNLP Issues: Speed and Repetition¶
The CoreNLP Docker container1 was initially released eight years ago and, not being embedded in the data science space, I didn’t realize how far the state of the art had progressed since its release in 20102
Luckily I am expecting a fairly simple drop-in replacement to the work I’ve completed so far - but a replacement is required. I’ll explain -
Here is how I’m using CoreNLP today:
;; Get OpenIE Triples from text:
(openie-triples "Novo Nordisk sheds its CEO, Jimbly Jumbles.")
;; Output:
'({:subject "Novo Nordisk", :relation "sheds", :object "its CEO"}
{:subject "its", :relation "CEO", :object "Jimbly Jumbles"}
{:subject "Novo Nordisk", :relation "sheds", :object "Jimbly Jumbles"})
;; Named Entity Extraction from text:
(ner "Novo Nordisk sheds its CEO, Jimbly Jumbles.")
;; Output:
'({:ner "ORGANIZATION", :text "Novo Nordisk"}
{:ner "TITLE", :text "CEO"}
{:ner "PERSON", :text "Jimbly Jumbles"})
Pretty good! It was fun to configure the CoreNLP functions to return this data, since it’s easy to write a closure to store a function to fire off these requests. The list of annotator dependencies3 in the CoreNLP documentation can almost be copy-pasted into the source code to form working functions.
(def lemma
(corenlp-function [:tokenize :ssplit :pos :lemma] :tokens))
(def ner
(corenlp-function [:tokenize :ssplit :pos :lemma :ner] :entitymentions))
(def openie-triples
(corenlp-function [:tokenize :ssplit :pos :lemma :depparse :natlog :openie] :openie))
Essentially, I convert these lists of keywords into the JSON instructions to pass to the CoreNLP server, and a string is passed in the body of the simple HTTP request.
By far, the Named Entity Recognition model (NER) takes the longest to run. All of this works reliably and reasonably quickly (though not quite quickly enough to process more than 120 articles an hour.) The real trouble is the output.
Example 1
‘News24 | Business Brief | Pepkor flags peppier profits; Novo Nordisk sheds its CEO. An overview of the biggest business developments in SA and beyond.’
OpenIE Triples:
| :subject | :relation | :object |
|-------------------------------|-----------|---------|
| Novo Nordisk | sheds | its CEO |
| biggest business developments | is in | SA |
Recognized Entities:
| :ner | :text |
|--------------|--------------|
| TITLE | CEO |
| ORGANIZATION | Novo Nordisk |
| ORGANIZATION | Pepkor |
Example 2
‘Earthquake alert (automated). TOKYO - The following is an earthquake alert issued by the Japan Meteorological Agency. Day and Time:…’
OpenIE Triples:
| :subject | :relation | :object |
|---------------|-----------|--------------------------------------------------------|
| The | is | earthquake alert issued by Japan Meteorological Agency |
| The | is | earthquake alert |
| The | issued by | Japan Meteorological Agency |
| The | is | earthquake alert issued |
| The following | issued by | Japan Meteorological Agency |
| The following | is | earthquake alert issued by Japan Meteorological Agency |
| The following | is | earthquake alert issued |
| The following | is | earthquake alert |
Recognized Entities:
| :ner | :text |
|----------------|-----------------------------|
| DURATION | Day |
| CAUSE_OF_DEATH | Earthquake |
| ORGANIZATION | Japan Meteorological Agency |
| CITY | TOKYO |
| CAUSE_OF_DEATH | earthquake |
Example 3
‘Japan’s Top Banks Break Profit Records as Interest Rates Rise. Japan’s three largest banking groups have all reported record net profits for the past fiscal year, with their combined earnings nearing 4 trillion yen. (News On Japan)’
OpenIE Triples:
| :subject | :relation | :object |
|----------|-----------|--------------------------------|
| Japan | ’s | Top Banks Break Profit Records |
| Japan | ’s | three largest banking groups |
Recognized Entities:
| :ner | :text |
|---------|----------------------|
| MONEY | 4 trillion yen |
| COUNTRY | Japan |
| DATE | the past fiscal year |
| NUMBER | three |
Example 4
‘Daily Tech News 15 May 2025. Top Story The Kids Online Safety Act is back and has the potential to change the internet - or to get struck down immediately over the obvious First and Fourth Amendment issues. (Tech Crunch) The bill has strong bipartisan and…’
OpenIE Triples:
| :subject | :relation | :object |
|-----------|----------------------------------|----------------------|
| Top Story | has | potential |
| bill | has | strong |
| internet | get struck down over | First issues |
| internet | get struck down immediately over | First issues |
| internet | get struck down immediately over | obvious First issues |
| internet | get struck down over | obvious First issues |
Recognized Entities:
| :ner | :text |
|---------|------------------------|
| DATE | 15 May 2025 |
| SET | Daily |
| ORDINAL | First |
| MISC | Kids Online Safety Act |
| ORDINAL | and Fourth |
As a final example - here’s where things can get really repetitious.
Example 5
‘News24 | Magudumana lawfully deported from Tanzania, says SCA – but one judge disagrees. Dr Nandipha Magudumana has lost her latest bid to challenge the legality of her deportation from Tanzania in the Supreme Court of Appeal (SCA) – a decision the State hopes will enable it to proceed with the Thabo Bester escape trial in July.’
OpenIE Triples:
| :subject | :relation | :object |
|----------------|--------------|----------------------------------------------------------------------|
| her bid | challenge | legality in Supreme Court |
| her bid | challenge | legality of her deportation from Tanzania in Supreme Court |
| her bid | challenge | legality of her deportation in Supreme Court of Appeal |
| her bid | challenge | legality of her deportation in Supreme Court |
| her bid | challenge | legality of her deportation from Tanzania |
| her bid | challenge | legality from Tanzania in Supreme Court |
| her bid | challenge | legality from Tanzania in Supreme Court of Appeal |
| her bid | challenge | legality in Supreme Court of Appeal |
| her bid | challenge | legality of her deportation from Tanzania in Supreme Court of Appeal |
| her bid | challenge | legality |
| her bid | challenge | legality of her deportation |
| her bid | challenge | legality from Tanzania |
| her latest bid | challenge | legality from Tanzania |
| her latest bid | challenge | legality from Tanzania in Supreme Court of Appeal |
| her latest bid | challenge | legality |
| her latest bid | challenge | legality from Tanzania in Supreme Court |
| her latest bid | challenge | legality of her deportation from Tanzania in Supreme Court of Appeal |
| her latest bid | challenge | legality in Supreme Court of Appeal |
| her latest bid | challenge | legality of her deportation |
| her latest bid | challenge | legality of her deportation in Supreme Court of Appeal |
| her latest bid | challenge | legality of her deportation from Tanzania in Supreme Court |
| her latest bid | challenge | legality in Supreme Court |
| her latest bid | challenge | legality of her deportation from Tanzania |
| her latest bid | challenge | legality of her deportation in Supreme Court |
| it | proceed with | Thabo Bester |
| legality | is in | Supreme Court of Appeal |
Recognized Entities:
| :ner | :text |
|--------------|-------------------------|
| DATE | July |
| PERSON | Nandipha Magudumana |
| ORGANIZATION | SCA |
| ORGANIZATION | Supreme Court of Appeal |
| COUNTRY | Tanzania |
| PERSON | Thabo Bester |
| PERSON | her |
| TITLE | judge |
| NUMBER | one |
I could try to tamp these down on my own and try to better group the entities, but it may be better to just try a different tool.
AllenNLP¶
This one was a dud. Dead on arrival and deprecated. The team stopped responding to bugs in a planned manner back in 2022, and now work on AI2 Tango .
version: '3.8'
services:
allennlp-openie:
image: allennlp/allennlp:latest
container_name: allennlp-openie
command: ["serve", "--port", "8000"]
ports:
- "8392:8000"
restart: unless-stopped
When launching, I found the library doesn’t even have a ‘server’ function anymore. DOA.
SpaCY¶
version: '3.8'
services:
spacyapi:
image: jgontrum/spacyapi:en_v2
ports:
- "1237:80"
restart: unless-stopped
Though a little less accurate in the first case, this system seems to be significantly faster than CoreNLP in this area.
(time
(json-body
(client/post spacy-url
{:body (json/write-str
{:text "News24 | Business Brief | Pepkor flags peppier profits; Novo
Nordisk sheds its CEO. An overview of the biggest business
developments in SA and beyond."
:model "en"})
:headers {:content-type "application/json"}})))
;; SpaCY Result, "Elapsed time: 26.117348 msecs"
[{:end 6, :start 0, :text "News24", :type "GPE"}
{:end 68, :start 56, :text "Novo Nordisk", :type "ORG"}
{:end 138, :start 136, :text "SA", :type "ORG"}]
(time
(ner "News24 | Business Brief | Pepkor flags peppier profits; Novo
Nordisk sheds its CEO. An overview of the biggest business
developments in SA and beyond2."))
;; CoreNLP Result, "Elapsed time: 4090.070472 msecs"
({:tokenBegin 5, :docTokenEnd 6, :nerConfidences {:ORGANIZATION 0.92924116518148}, :tokenEnd 6,
:ner "ORGANIZATION", :characterOffsetEnd 32, :characterOffsetBegin 26, :docTokenBegin 5,
:text "Pepkor"}
{:tokenBegin 10, :docTokenEnd 12, :nerConfidences {:ORGANIZATION 0.9979907226449}, :tokenEnd 12,
:ner "ORGANIZATION", :characterOffsetEnd 68, :characterOffsetBegin 56, :docTokenBegin 10,
:text "Novo Nordisk"}
{:docTokenBegin 14, :docTokenEnd 15, :tokenBegin 14, :tokenEnd 15,
:text "CEO", :characterOffsetBegin 79, :characterOffsetEnd 82,
:ner "TITLE"})
SpaCY’s entity recognition is very good for its time budget.
SpaCY Example
‘Eighty Years On, Okinawa Remembers the Battle of Sugar Loaf Hill. Eighty years have passed since the end of World War II, yet the memories of its fiercest battles continue to echo in the heart of Okinawa. The district of Omoromachi in central Naha, now a lively urban hub filled with people, was once the site of one of the bloodiest clashes of the Battle of Okinawa—the Battle of Sugar Loaf Hill. (News On Japan)’
;; Recognized Entities:
("Eighty Years"
"the Battle of Sugar"
"Eighty years"
"World War II"
"Okinawa"
"Omoromachi"
"Naha"
"one"
"Japan")
SpaCY also provides categories, but it’s easier to de-duplicate the shorter keywords it produces than with CoreNLP.
Performance¶
Taking a peek at my docker containers - this is well within my memory
budget to run both, and I have more memory than real CPU power per
docker stats
CONTAINER NAME CPU % MEM USAGE MEM %
-------------------------------------------------------
spacy_nlp-spacyapi-1 0.03% 288MiB 1.81%
corenlp-corenlp-1 0.05% 3.585GiB 23.11%
main-postgres-1 3.35% 287.3MiB 1.81%
observer-observer-1 4.82% 1.205GiB 7.77%
admin-stack_traefik_1 0.01% 104.5MiB 0.66%
Wow! CoreNLP uses 3.5GB of RAM, an order of magnitude higher than the 300mb comsumed by SpaCY, all while running its pipelines in an order of magnitude more time. Doubtlessly, the composable pipeline that CoreNLP offers is also more complex.
Using an LLM?¶
Below are the published free tier limits as of May 16, 2025.
- RPM - Requests per minute
- RPD - Requests per day
- TPM - Tokens per minute
- TPD - Tokens per day
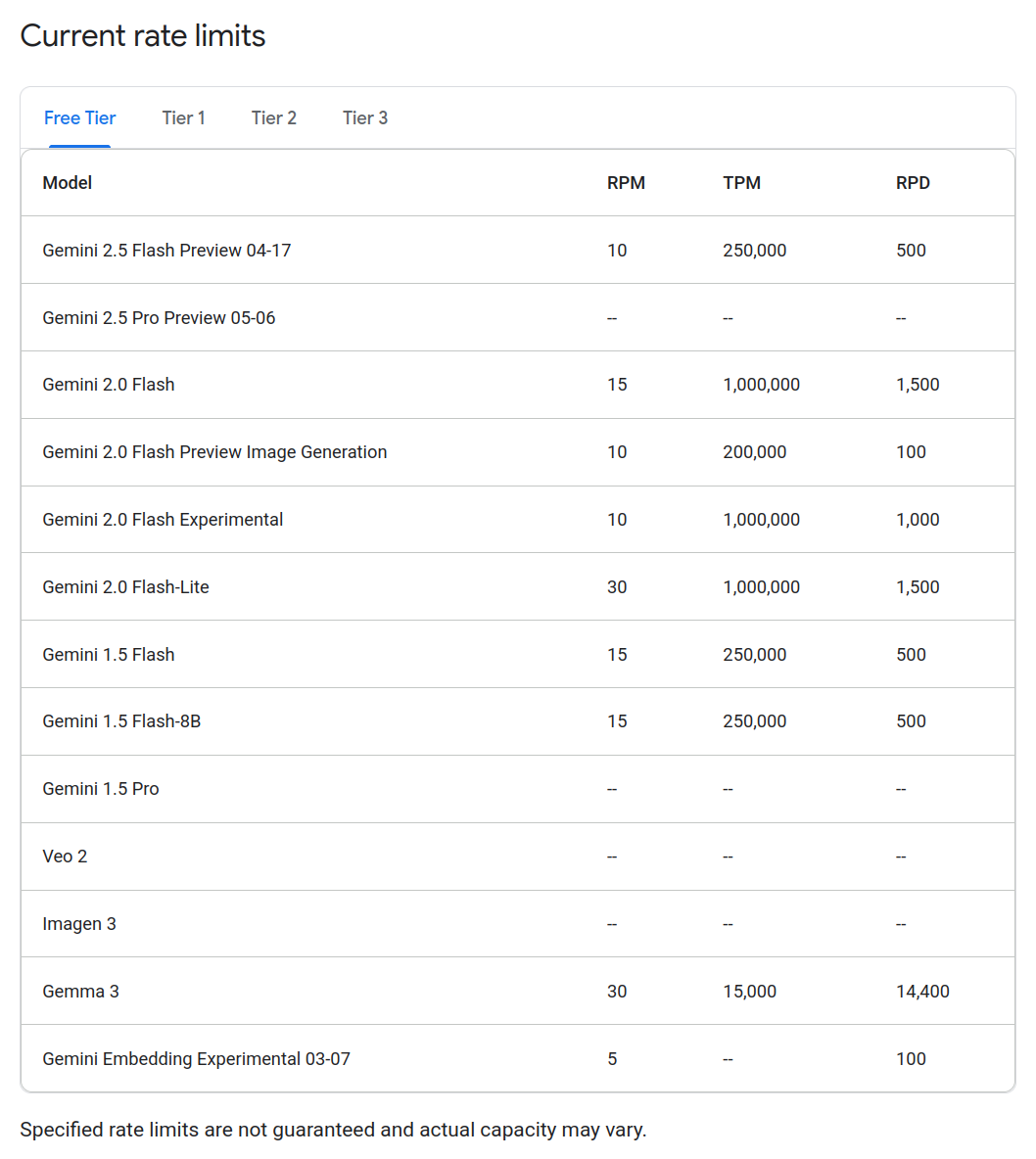
With up to 20,000 ingested articles per day, this is insufficient to make multiple calls for each produced article entering Observer.
LLM Development is clearly hurting the research and development of these algorithms - does it matter?
Per this paper, it seems prompting GPT-like models outperform classical OpenIE extractors anyhow:
“Large Language Models are Zero-Shot Reasoners”
By Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, Yusuke Iwasawa
https://arxiv.org/abs/2205.11916
Pretrained large language models (LLMs) are widely used in many sub-fields of natural language processing (NLP) and generally known as excellent few-shot learners with task-specific exemplars. Notably, chain of thought (CoT) prompting, a recent technique for eliciting complex multi-step reasoning through step-by-step answer examples, achieved the state-of-the-art performances in arithmetics and symbolic reasoning, difficult system-2 tasks that do not follow the standard scaling laws for LLMs.
While these successes are often attributed to LLMs’ ability for few-shot learning, we show that LLMs are decent zero-shot reasoners by simply adding “Let’s think step by step” before each answer. Experimental results demonstrate that our Zero-shot-CoT, using the same single prompt template, significantly outperforms zero-shot LLM performances on diverse benchmark reasoning tasks including arithmetics (MultiArith, GSM8K, AQUA-RAT, SVAMP), symbolic reasoning (Last Letter, Coin Flip), and other logical reasoning tasks (Date Understanding, Tracking Shuffled Objects), without any hand-crafted few-shot examples, e.g. increasing the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with large InstructGPT model (text-davinci-002), as well as similar magnitudes of improvements with another off-the-shelf large model, 540B parameter PaLM.
The versatility of this single prompt across very diverse reasoning tasks hints at untapped and understudied fundamental zero-shot capabilities of LLMs, suggesting high-level, multi-task broad cognitive capabilities may be extracted by simple prompting. We hope our work not only serves as the minimal strongest zero-shot baseline for the challenging reasoning benchmarks, but also highlights the importance of carefully exploring and analyzing the enormous zero-shot knowledge hidden inside LLMs before crafting finetuning datasets or few-shot exemplars.
I would speculate that many classical computing methods will soon cease to progress as LLM prompting overtakes classical computer science NLP methods.
Notes¶
- I’m kind of stuck. Where to from here?
- I can generate reasonable triples with CoreNLP
- I can generate reasonable entities with CoreNLP
- I can generate entities fast with SpaCY
- How can I use these approaches together to create accurate triples?
- ChatGPT says:
- Consider https://github.com/Babelscape/rebel
- Tune an LLM for RDF triple generation
- You can use the SpaCY dependency parsing API with pattern matching to get the output you want, allegedly.
- https://github.com/zjunlp/DeepKE is also mentioned and has great docs
- This article has a great walkthrough of deploying any model to a container https://medium.com/analytics-vidhya/deploying-a-nlp-model-with-docker-and-fastapi-d972779d8008
- Generally it looks like this task is now called Knowledge Base Population (KBP) and not just NLP/RDF.
- Complete the original goal first (triples)
Conclusion¶
I’ll stick to SpaCY for keyword recognition for now:
- It is much better in terms of speed and memory consumption
- Keywords are still good enough to track over time
- I’ll wait for my own LLM infrastructure to build knowledge graphs
- CoreNLP produces data that is too messy to be useful for a knowledge graph without further exploration and tuning
nlpbox/corenlp hub.docker.com ↩︎
“CoreNLP Release History” stanfordnlp.github.io ↩︎
“CoreNLP Annotator Dependencies” stanfordnlp.github.io ↩︎