I have been running Observer for over a year now. Given that it is the Christmas season - a time of relaxation, remembering our short time here and eternal things done for us, It is a good opportunity to look back and draw some lessons from a year of hacking on this thing.
Let’s answer a few questions:
- How much data did I collect?
- Was I able successfully extract tags from headlines?
- What will I be moving forwards with?
Data Volume¶
A simple check with du on my PostgreSQL folder reveals about 11GB of
data consumed.
du -hs <postgres data folder> #=> 11.2G
What about the consistency and quality of that data? Let’s run a few queries to check within the Postgres database.
select count(*) from keywords.terms; --> 2,023,694
select count(*) from media.items; --> 8,198,996
SELECT
schema_name,
relname,
pg_size_pretty(table_size) AS size,
table_size
FROM (
SELECT
pg_catalog.pg_namespace.nspname AS schema_name,
relname,
pg_relation_size(pg_catalog.pg_class.oid) AS table_size
FROM pg_catalog.pg_class
JOIN pg_catalog.pg_namespace ON relnamespace = pg_catalog.pg_namespace.oid
) t
WHERE schema_name NOT LIKE 'pg_%'
ORDER BY table_size DESC;
| schema_name | relname | size | table_size |
|--------------------+------------------------------------------+------------+------------|
| media | items | 5088 MB | 5335146496 |
| media | idx_media_item_uri_source_unique | 703 MB | 737427456 |
| keywords | terms_in_media_pkey | 616 MB | 645808128 |
| media | idx_media_item_uri_institution_unique | 614 MB | 643923968 |
| keywords | terms_in_media | 600 MB | 628809728 |
| media | idx_media_item_uri | 598 MB | 626941952 |
| keywords | daily_frequencies | 332 MB | 348340224 |
| keywords | daily_frequencies_id_keyword_day_key | 263 MB | 275742720 |
| media | idx_media_item_posted | 220 MB | 230334464 |
| media | items_pkey | 209 MB | 219201536 |
| media | idx_media_item_created | 181 MB | 189399040 |
| keywords | daily_frequencies_pkey | 139 MB | 146104320 |
| keywords | terms | 121 MB | 127082496 |
| keywords | terms_label_term_key | 107 MB | 112164864 |
| media | idx_media_item_source | 85 MB | 89604096 |
| keywords | idx_daily_frequencies_day | 51 MB | 53673984 |
| keywords | terms_pkey | 43 MB | 45465600 |
| analysis | six_hour_summaries | 2232 kB | 2285568 |
| media | sources | 208 kB | 212992 |
| analysis | six_hour_summaries_pkey | 144 kB | 147456 |
| media | institutions | 88 kB | 90112 |
| media | idx_media_source_url | 56 kB | 57344 |
| media | sources_pkey | 40 kB | 40960 |
| media | idx_institution_urlkey | 32 kB | 32768 |
| public | users_pkey | 16 kB | 16384 |
| public | ux_users_email | 16 kB | 16384 |
| public | schema_migrations_id_key | 16 kB | 16384 |
| media | institutions_pkey | 16 kB | 16384 |
| media | idx_media_text_analysis_v1_item | 8192 bytes | 8192 |
| media | text_analysis_v1_pkey | 8192 bytes | 8192 |
| media | keywords_id_seq | 8192 bytes | 8192 |
| media | idx_through_keywords_to_text_analysis_v1 | 8192 bytes | 8192 |
| media | keywords_pkey | 8192 bytes | 8192 |
| media | sources_id_seq | 8192 bytes | 8192 |
| media | institutions_id_seq | 8192 bytes | 8192 |
| keywords | daily_frequencies_id_seq | 8192 bytes | 8192 |
| keywords | terms_id_seq | 8192 bytes | 8192 |
| media | items_id_seq | 8192 bytes | 8192 |
| analysis | six_hour_summaries_id_seq | 8192 bytes | 8192 |
| media | text_analysis_v1_id_seq | 8192 bytes | 8192 |
What about consistency?
select count(id) as items,
date_trunc('month', created) as month
from media.items
group by month
order by month;
| items | month |
|--------+---------|
| 305954 | 2024-09 |
| 484560 | 2024-10 |
| 533889 | 2024-11 |
| 429309 | 2024-12 |
| 474681 | 2025-01 |
| 579925 | 2025-02 |
| 653998 | 2025-03 |
| 628588 | 2025-04 |
| 646642 | 2025-05 |
| 600735 | 2025-06 |
| 614814 | 2025-07 |
| 505834 | 2025-08 |
| 533773 | 2025-09 |
| 534749 | 2025-10 |
| 476398 | 2025-11 |
| 194795 | 2025-12 |
Text Analysis Services¶
Stanford CoreNLP and SpaCY are both pre-LLM natural language processing tools. My pragmatic goal was to find a library or container to extract keywords and relationships from headlines to build a knowledge graph. These days, graph RAG utilizes many of the concepts I was moving towards to construct semantic knowledge graphs of the data they ingest.
The service to extract keywords and triples also had to run on fairly ancient hardware - a 3rd gen dual-core Intel Core i3 processor. The hardware situation is now halfway remedied, and I have added a Mac Mini to my server closet to run basic low-cost inference, so this constraint is not as pressing as it was at the beginning of the year.
To summarize, my goals:
- I need a method to extract keywords and triples
- It has to run in a container on old hardware
I spun both up internally with independent compose files.
CoreNLP¶
services:
corenlp:
image: nlpbox/corenlp
restart: unless-stopped
ports:
# external:internal
- "9209:9000"
environment:
JAVA_XMX: "4g"
networks:
- core-nlp-network
networks:
core-nlp-network:
external: true
From here, I wrote a Clojure wrapper to pass strings and return data for openie-triples and named entity recognition procedures that are supported by CoreNLP:
(openie-triples "Novo Nordisk sheds its CEO, Jimbly Jumbles.")
;; Result:
'({:subject "Novo Nordisk", :relation "sheds", :object "its CEO"}
{:subject "its", :relation "CEO", :object "Jimbly Jumbles"}
{:subject "Novo Nordisk", :relation "sheds", :object "Jimbly Jumbles"})
(ner "Novo Nordisk sheds its CEO, Jimbly Jumbles.")
;; Result:
'({:ner "ORGANIZATION", :text "Novo Nordisk"}
{:ner "TITLE", :text "CEO"}
{:ner "PERSON", :text "Jimbly Jumbles"})
Despite early success, I ended up abandoning CoreNLP long ago due to its inability to parse many headlines, which are not written in grammatically correct English. You may also notice some superfluous results above - I don’t need to know that the CEO of “it’s” is a guy named Jimbly. It is very tough to programmatically determine the value of these edges and nodes.
A request to CoreNLP also took 4 seconds, which without parallelism would just about fit the 20,000 article headlines per day into the ~86,400 seconds that make up one day.
(time ;; "Elapsed time: 4090.070472 msecs"
(ner "News24 | Business Brief | Pepkor flags peppier profits;
Novo Nordisk sheds its CEO. An overview of the biggest
business developments in SA and beyond2."))
;; Result:
({:tokenBegin 5, :docTokenEnd 6, :nerConfidences {:ORGANIZATION 0.92924116518148}, :tokenEnd 6,
:ner "ORGANIZATION", :characterOffsetEnd 32, :characterOffsetBegin 26, :docTokenBegin 5,
:text "Pepkor"}
{:tokenBegin 10, :docTokenEnd 12, :nerConfidences {:ORGANIZATION 0.9979907226449}, :tokenEnd 12,
:ner "ORGANIZATION", :characterOffsetEnd 68, :characterOffsetBegin 56, :docTokenBegin 10,
:text "Novo Nordisk"}
{:docTokenBegin 14, :docTokenEnd 15, :tokenBegin 14, :tokenEnd 15,
:text "CEO", :characterOffsetBegin 79, :characterOffsetEnd 82,
:ner "TITLE"})
SpaCY¶
services:
spacyapi:
image: jgontrum/spacyapi:en_v2
ports:
- "9210:80"
restart: unless-stopped
networks:
- spacy-network
networks:
spacy-network:
external: true
SpaCY is a classical machine-learning swiss army knife.
[SpaCY has] components for named entity recognition, part-of-speech tagging, dependency parsing, sentence segmentation, text classification, lemmatization, morphological analysis, entity linking and more
I ended up utilizing the entity-recognition, which could run 100 items through in 21 seconds. This was a much more acceptable speed than 4 seconds per item. Below are some output examples.
;; Basic entity extraction
(spacy-get-entities "BREAKING NEWS: Trump says he 'straightened out' rare earth-related issues with Xi.")
;; Result
[{:end 20, :start 15, :text "Trump", :type "PERSON"}
{:end 81, :start 79, :text "Xi", :type "PERSON"}]
;; Dependency extraction
(spacy-get-dependencies "BREAKING NEWS: Trump says he 'straightened out' rare
earth-related issues with Xi.")
;; Result:
{:arcs [{:dir "left", :end 2, :label "nsubj", :start 1, :text "Trump"}
{:dir "left", :end 4, :label "nsubj", :start 3, :text "he '"}
{:dir "right", :end 4, :label "ccomp", :start 2, :text "straightened"}
{:dir "right", :end 5, :label "prt", :start 4, :text "out'"}
{:dir "right", :end 6, :label "dobj", :start 4, :text "rare earth-related issues"}
{:dir "right", :end 7, :label "prep", :start 6, :text "with"}
{:dir "right", :end 8, :label "pobj", :start 7, :text "Xi."}],
:words [{:tag "NN", :text "BREAKING NEWS:"}
{:tag "NNP", :text "Trump"}
{:tag "VBZ", :text "says"}
{:tag "PRP", :text "he '"}
{:tag "VBD", :text "straightened"}
{:tag "RP", :text "out'"}
{:tag "NNS", :text "rare earth-related issues"}
{:tag "IN", :text "with"}
{:tag "NNP", :text "Xi."}]}
;; You'll need to store a dictionary with a guide for these tags!
(spacy-get-entities "Early Bitcoin Miner Awakens $77 Million Fortune After 15-Year
Slumber | A pioneering Bitcoin miner has stirred their dormant
cryptocurrency holdings for the first time in 15 years. Arkham
Intelligence reported this unprecedented activity, which has
sent ripples through the crypto community. The miner’s
patience has yielded an astounding $77 million windfall from
their early involvement in Bitcoin. The miner acquired their
Bitcoin through mining in")
;; Result:
'[{:end 19, :start 6, :text "Bitcoin Miner", :type "PERSON"}
{:end 39, :start 28, :text "$77 Million", :type "MONEY"}
{:end 61, :start 54, :text "15-Year", :type "CARDINAL"}
{:end 116, :start 109, :text "Bitcoin", :type "GPE"}
{:end 186, :start 181, :text "first", :type "ORDINAL"}
{:end 203, :start 195, :text "15 years", :type "DATE"}
{:end 224, :start 205, :text "Arkham Intelligence", :type "ORG"}
{:end 374, :start 349, :text "an astounding $77 million", :type "MONEY"}
{:end 423, :start 416, :text "Bitcoin", :type "GPE"}
{:end 457, :start 450, :text "Bitcoin", :type "GPE"}]
;; Some Key Categories
{
:PERSON "People, including fictional"
:GPE "Countries, cities, states"
:LOC "Non-GPE locations, mountain ranges, bodies of water"
:ORG "Companies, agencies, institutions, etc."
:MONEY "Monetary values, including unit"
}
Though this is a huge improvement in performance, and the output is really great, but you’ll notice some key problems with the data above. Bitcoin isn’t a country/city/state, it’s a money.
When storing keywords, my initial implementation made room for different capitalization of terms, which results in a variety of different casings and labels for a single word. This presents a new and obvious problem to solve - how related are these terms?
select * from keywords.terms where lower(term) = 'trump' order by id desc limit 20;
id | label | term
---------+-------------+-------
1840200 | PERSON | TrUmP
1609960 | DATE | Trump
618151 | QUANTITY | Trump
347430 | ORG | TRUMP
340414 | PRODUCT | TRUMP
136251 | MONEY | Trump
94973 | WORK_OF_ART | TRUMP
88447 | FAC | Trump
68589 | EVENT | Trump
55607 | MONEY | TRUMP
45970 | PERSON | TRUMP
24686 | LANGUAGE | Trump
16995 | LAW | Trump
3592 | CARDINAL | Trump
2837 | ORG | Trump
1676 | GPE | Trump
532 | LOC | Trump
281 | WORK_OF_ART | Trump
144 | PRODUCT | Trump
71 | PERSON | Trump
Furthering this problem - groups of words are often misidentified as names, filling up the database with low quality data. Luckily the frequency of these detections is relatively low.
select * from keywords.terms
where lower(term) like '%trump%'
and label = 'PERSON' -- There are many other keyword-labels with 'Trump'
order by id desc limit 200;
id | label | term
---------+--------+---------------------------------------------------------
2023762 | PERSON | Trump Praises Indian-
2023226 | PERSON | Trump Congress
2023041 | PERSON | Sidestep Trump
2022539 | PERSON | Trump Attacks Clinton
2021844 | PERSON | Trump Memo
2021232 | PERSON | Trump Kennedy Center
2016537 | PERSON | TRUMP Trump
2014908 | PERSON | Donald Trump Reiterates
2014786 | PERSON | Donald Trump Reiterates '
2014665 | PERSON | Trump Speech Thread
2013339 | PERSON | lets Trump
2010721 | PERSON | Rubio Calls Trump
2010571 | PERSON | Trump Orders Blockade
2010564 | PERSON | Nicolás Maduro Donald Trump
2008667 | PERSON | Trumps praise
2008360 | PERSON | Donald Trumpis
2008356 | PERSON | Susie Wiles Acknowledges Trump’s
2008138 | PERSON | Trump Expands The Toolkit
2007744 | PERSON | Trump Jr.’s
2007375 | PERSON | Trump Deflects Blame
2007048 | PERSON | Thinks Trump
2006874 | PERSON | Trump Sues BBC
2006685 | PERSON | Donald Trump Sues BBC
2005580 | PERSON | Trump Launches Political Attack on
2002889 | PERSON | Trump Pauses White House
2000309 | PERSON | Sue Trump Admin
2000268 | PERSON | Trump Says '
2000254 | PERSON | Trump Prays
2000127 | PERSON | Donald Trump
1999340 | PERSON | Trumpkin
1997712 | PERSON | Trump To Clinton
1997351 | PERSON | Will Trump '
1996619 | PERSON | Warm Trump-Modi
...etc, etc, etc - this list goes on for a long time.
Tagging Success¶
Long story short - it’s working alright, but not well. Trends are clearly visible when a global power decides to immolate a city, or a celebrity is shot, but many of the tags are superflous and not of note.

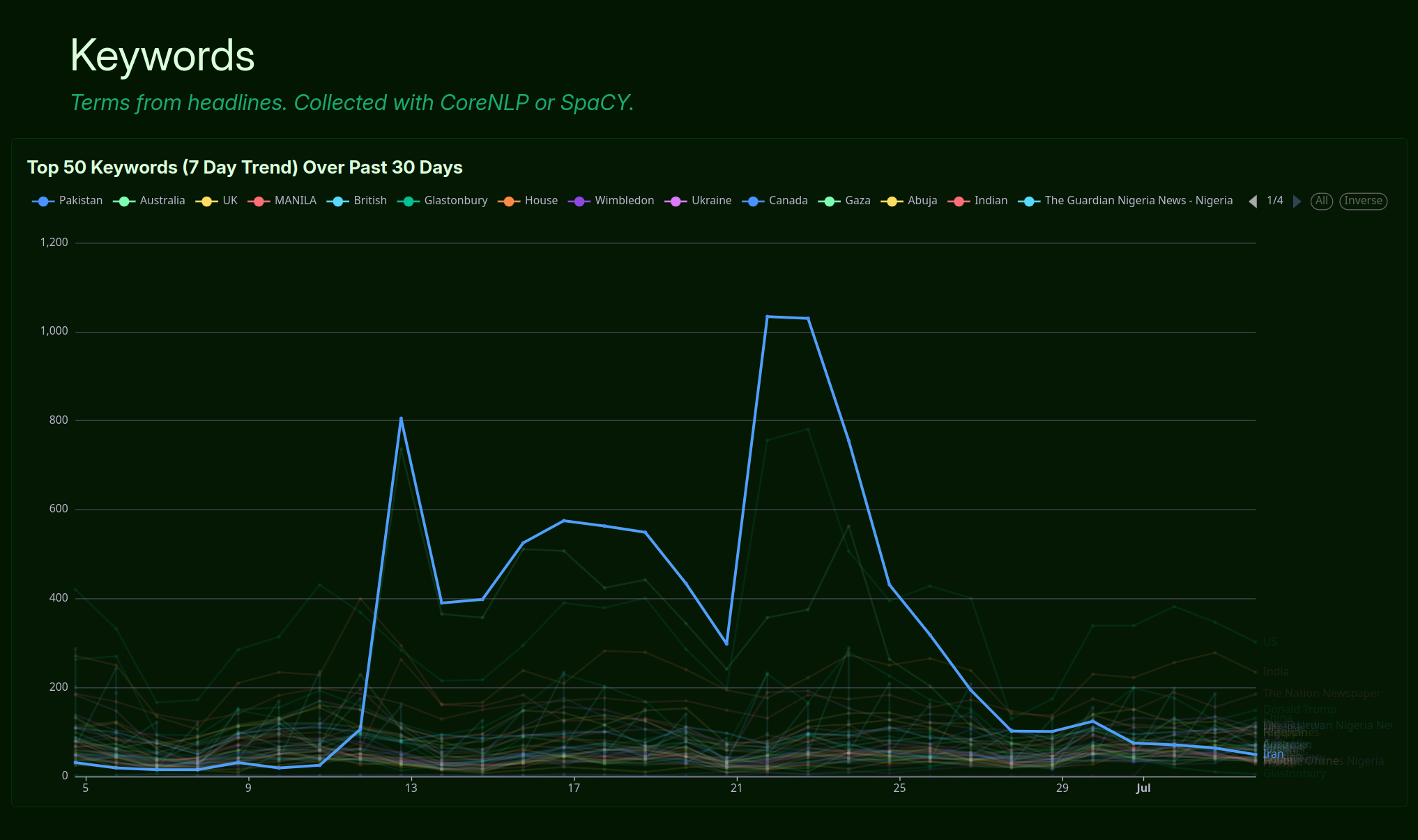
I have not yet applied an algorithm to my frontend to remove tags that have not broken above or below a standard deviation (or any sort of anomaly detection algorithm) but would like to shortly.
With current collection methods, here are the top terms that I am detecting and associating with incoming articles. Note that many of these terms, sometimes collected hundreds of thousands of times, have little to no meaning at all. Further data processing is required to distill the data captured in this layer into meaningful insights.
select count(tim.id_item) as media_items,
t.label,
t.term
from keywords.terms_in_media tim
left join keywords.terms t
on t.id = tim.id_keyword
group by t.id
order by media_items desc
limit 100;
count of
related
media_items | label | term
--------------+----------+-------------------------------------
293,009 | ORDINAL | first
122,973 | GPE | US
86,930 | CARDINAL | two
77,687 | GPE | India
76,296 | CARDINAL | one
72,011 | ORG | The Nation Newspaper
63,800 | PERSON | Trump
63,150 | PERSON | Donald Trump
59,846 | DATE | 2025
59,155 | DATE | Monday
58,955 | DATE | Tuesday
57,544 | ORG | World News
57,519 | ORG | The Guardian Nigeria News - Nigeria
56,873 | DATE | Wednesday
55,109 | DATE | Thursday
52,443 | DATE | Friday
47,183 | GPE | Nigeria
46,565 | GPE | UK
46,012 | DATE | today
45,538 | CARDINAL | three
44,721 | GPE | Philippines
44,694 | GPE | U.S.
43,906 | DATE | Sunday
41,523 | DATE | Saturday
40,203 | GPE | China
39,396 | PRODUCT | Trump
37,111 | ORDINAL | second
35,166 | GPE | Russia
34,844 | GPE | Ukraine
34,443 | GPE | Israel
33,688 | NORP | Nigerian
33,221 | GPE | Australia
31,060 | GPE | Canada
27,563 | CARDINAL | four
27,160 | DATE | 2024
27,107 | NORP | Indian
25,625 | CARDINAL | 2
25,088 | NORP | Russian
23,706 | CARDINAL | five
23,292 | GPE | Gaza
22,981 | CARDINAL | Two
22,522 | CARDINAL | One
21,724 | ORG | MANILA
21,706 | GPE | Pakistan
21,155 | NORP | Israeli
20,939 | ORG | Premium Times Nigeria
20,251 | CARDINAL | 3
19,999 | NORP | Chinese
19,852 | CARDINAL | 10
19,794 | NORP | American
19,183 | GPE | Japan
18,668 | NORP | Australian
18,372 | GPE | London
18,274 | GPE | Iran
18,177 | NORP | British
17,975 | LOC | Trump
17,750 | ORG | Congress
17,510 | ORDINAL | third
17,167 | GPE | News24
16,998 | DATE | this week
16,883 | GPE | the United States
16,868 | DATE | this year
16,724 | ORG | Senate
16,293 | LOC | Europe
16,230 | ORG | NME
15,968 | CARDINAL | six
15,944 | GPE | Abuja
15,921 | GPE | South Africa
15,874 | CARDINAL | 5
15,522 | ORG | Tribune Online
15,439 | NORP | Canadian
15,351 | GPE | England
15,340 | CARDINAL | 1
14,934 | GPE | France
14,615 | NORP | Nigerians
14,354 | ORG | APC
14,311 | PERSON | Bola Tinubu
14,021 | GPE | Delhi
13,532 | GPE | Ireland
13,489 | NORP | French
13,442 | TIME | night
13,355 | DATE | 2023
13,254 | DATE | 2026
12,866 | ORG | EU
12,654 | DATE | Today
12,500 | ORG | Hamas
12,438 | GPE | Washington
12,407 | CARDINAL | 4
12,302 | CARDINAL | Three
12,172 | GPE | Sydney
12,158 | ORG | BJP
12,148 | CARDINAL | 2024
12,146 | NORP | Instagram
12,125 | DATE | last year
11,993 | GPE | Britain
11,941 | DATE | yesterday
11,910 | NORP | European
11,865 | TIME | morning
11,791 | DATE | last week
11,689 | ORG | SA
(100 rows)
Conclusion & Next Steps¶
While I haven’t spent nearly the amount of time I would have liked to on this side project, I have learned a lot reading about traditional NLP methods and discovering the strengths and weaknesses of different approaches.
Unfortunately, LLMs are excellent one-shot triple extractors, and I imagine the amount of research pointed towards classical NLP and these types of methods will drop to nearly zero as a result.
My next steps for this program is to migrate my database to a newer version of PostgreSQL with PostGIS and PGVector, in order to plot these news articles based on any locations mentioned in the headline and body, and to integrate a vector search to group similar headlines.
Most importantly - I will begin utilizing my own self-hosted LLMs, breaking reliance on services hosted by big tech and eliminating my rate limits. This may come at the expense of speed, quality, and context window.
Here’s to another year - happy hacking!